

 Állítsd be, hogy az Economx az elsők között legyen a Google-találatokban!
Állítsd be, hogy az Economx az elsők között legyen a Google-találatokban!
A hazánkban 2001 óta jelenlévő országos kompetenciamérés elsődleges célja a 6-, 8-, 10. osztályos diákok logika készségeinek mérése. Ennek eredményeit a későbbiekben összevetik az iskolák, illetve a különböző régiók között is. Mi történik azonban, ha az iskolapadban nem egy gyerek, hanem a mesterséges intelligencia „ül”?
Erre a kérdésre adott választ a PeakX csoport kutatása, amely azt vizsgálta, hogyan is teljesítenek a népszerű AI modellek a diákok által megírt teszteken. Az AI modell teszteléshez a vállalat emberei 70 szövegértési és 70 matematikai feladatot használtak, kiegészítve történelem, természettudomány és digitális kultúra kérdésekkel, amelyeket később egy objektív pontozási rendszerrel értékelték.
Az AI kompetenciáját 4 rendszer (benchmark) alapján vizsgáltuk, vagyis az MMLU – amely 57 különböző tudományterületet ölel fel, köztük a matematikát, filozófiát, jogot és orvostudományokat – HumanEval, illetve a GPQA, és a MATH segítségével
– mondta el Sajtos István, a Peak Innovations Innovációs igazgatója.
A tesztek 3 szempontot vettek figyelembe: a feladatmegoldások gyorsaságát, az erőforrásigényt és költségeket, illetve a pontosságot.
Hogyan is teljesít a diák (AI) az iskolapadban?
A PeakX csapata az alábbi összeállítást készítette az AI modellekről és a teljesítményükről:
- OpenAI o1 - Kiemelkedő általános tudással rendelkezik, erős szövegértési és matematikai képességekkel, viszont lassú és drága.
- Anthropic Sonnet 3.7 - Kiváló szövegértési teljesítményt mutatott, gyors és költséghatékony, azonban komplex matematikai feladatokban gyengébb.
- xAI Grok2 - Rendkívül gyors és olcsó, de a matematikai feladatok terén kifejezetten rosszul teljesített.
- Gemini 2.0 „Flash” - Kiemelkedő szövegértési képességekkel bír, de az összetettebb következtetési feladatokban alulmaradt.
- Mistral Large - Relatív olcsó, de általános tudása korlátozottabb.
- Deepseek - Olcsó és gyors, kiemelkedő következtetési képességekkel, de nem képes vizuális elemzésre, és hajlamos fura hibákat véteni.
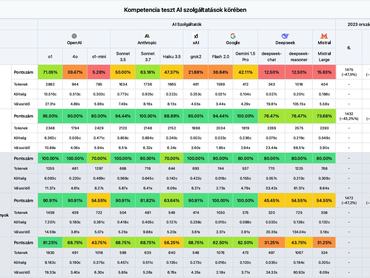
Sajtos István a sajtótájékoztatót összegezve elmondta, bár az érvelő modellek lassabbak és drágábbak, minden kategóriában jobb teljesítményt tudtak nyújtani AI társaiknál. Az eredmények alapján le lehet vonni a következtetést, miszerint a nagy nyelvi modellek a problémamegoldó és analitikus készségeket igénylő területeken még nem képesek helyettesíteni az emberi tudást. Ez a lemaradás főként a komplex matematikai készségeket igénylő feladatokban mutatkozik meg.

A legtöbb AI modellnek megvannak a maga korlátai, hiszen nem tudnak determinisztikus válaszokat adni, vagyis az egymás után feltett két ugyanolyan kérdésre adott válaszuk gyakran különbözik. Egy másik nagy akadály még, hogy egyes típusok (például a DeepSeek) nehezen fejti meg a vizuális elemeket, amely azonban a magyar kompetenciamérés szerves részét képezi.
Az Innovációs igazgató elmondta, komoly hátránynak számít még, hogy a különböző modelleknek meggyűlik a baja a magyar nyelv megértésével, így emiatt is előfordulhatnak hibák. A kapott eredmények mindenesetre remek ugródeszkát jelentenek jövőbeli AI fejlesztésekhez. Az viszont már most elmondható, hogy a mesterséges intelligencia kiváló lehetőség a tudás bővítésére, illetve gyors megszerzésére, de fontos kiemelni, hogy az emberi tudást nem képes helyettesíteni.
Bővebben>>>